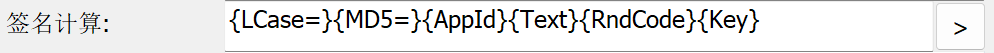硝酸羊
硝酸羊 发表的所有内容
-
我的话并没有什么伟大不伟大的,一开始就是自己想爽才做的汉化>_>
-
推荐你一个Steam刚上的点击游戏 (the) Gnorp Apologue 贼魔性而且内容挺多的,就是没有中文=^=
-
不是应该今天吃吗,今天是冬至夜,会当年来过。晚上一起吃火锅喝冬酿酒。上海那边貌似会吃饺子?
-
这就不得不推荐PICO PARK了,我之前也和朋友联机过,挺便宜的(22块),而且支持的人多,十几个人一起都行。你可以去b站上看看这个游戏是怎么样的。 这个游戏人多了更好玩,可以体会到十几个人凑不出一个脑子的快乐。 就是流程比较短,可能几个小时就通关了。虽然也有对抗但是也玩不了太久。但联机的几个小时是真的很乐
-
这次不聊技术,说点别的。 一开始研究汉化,也是看到特别喜欢的游戏,想做了翻译自己爽,然后不知不觉花了很多时间研究。于是就想着,反正花这么多时间了,而且也没人做过,不如就发出来算了。 可是发出来有个问题:自己玩的话,有bug最多再改就是了,发出来给大伙玩,就得确保没有bug才行。 我第一次做的汉化,为了保持初见的新鲜感,是先做了汉化再玩的。然后我一口气做了两部,只完整测试了一部,另一部还没有测。我自信觉得第一部没啥问题第二步也不会有啥问题,而且在汉化软件里也检查过没有英文字符残留(这个游戏引擎汉化之后报错主要集中在文本有残余英文字符),所以就直接发了。 结果。。。没过多久评论区老哥就发现有bug了。。。一看是一句话里有个反斜杠残留。不过已经是周一了就只改了这一个然后重发。 然后。。。第二天又发现有bug。。。这次虽然开游戏测了,也改了,可是第三天评论区又反馈有bug。我一看,那段出问题的对话是不一定触发的,被我之前跳过了。。。 之后又改,目前老哥没有再反馈bug。 所以说发出来的东西还是一定要自己完整检查一遍。 现在我又做了另外两部的翻译,不过这次我等自己有空玩完再发了,另外按论坛老哥的建议也去研究下别的翻译引擎。
-
懂力。不过淘宝上会不会风险比较大?那还是等我润出去再弄这个吧
-
我也觉得gpt翻译质量最高,但是gpt的API不是要绑定海外信用卡吗,这我实在弄不来 还有让gpt一次跑十几万字的*那种*翻译真的不会被自主规制吗
-
上次吐槽贴竟然有这么多人回复,那为了水节操让大伙看个乐就再发一帖把 ——————————————————————————————————————————————————————————————————— 这次要吐槽的是配置翻译引擎的问题,以及我个人对国内各个翻译引擎的感受。 因为不太会日语,所以现在只能用机翻汉化(就是懒)(在学了在学了)。之前用团子翻译器的时候折腾过几个翻译引擎,个人觉得日翻中的质量排序是:有道最好,彩云略次之,百度腾讯和其他的都一般般。 使用Wanfu大佬制作的在线翻译宏(2023.02.06版)配置翻译引擎,百度的还算简单,直接填ID和密钥就行,小牛搜狗的质量不比百度高就不搞了,Google的挂上科学上网就能用(不过是公开接口)。想配置有道的翻译接口,翻译宏只提供了有道V1.1的接入方式,然而人家已经开始用V3了,V3的签名生成要求对翻译源文本拆分和拼接。在线翻译宏只能提供比较简单的签名计算方式,有道的这个实在是不知道怎么生成。研究了半天怎么往这个窗口里塞JS脚本,然而最后还是一无所获 腾讯的签名方式比有道还复杂,直接放弃。 最后妥协了,就用百度的垃圾翻译作一次翻译,Google作二次翻译(修正百度没翻的、翻错的) 然后就是各大翻译引擎提供商的支持文档:腾讯的支持文档做的非常详细,有道的也很详细,百度的相对简短一点,但都算比较实用。还去看了彩云的支持文档,那真是主打一个能不写就不写。。。翻译API的文档标题,美名其曰“五分钟学会彩云小译 API”,给了Bash和Python两段Demo,然而什么参数名称、接入方式、接入参数全都没写。完全用不了啊kora 总之就是在翻译引擎上折腾了相当长的时间,几乎完全没有收获,最后直接躺了。大概学过计算机的话会轻松很多吧

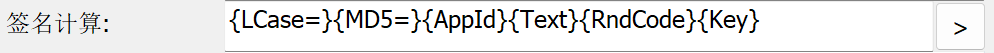

-
坐标江南地区,这个冬天确实冷得不行,寒潮一来温度都已经零下了,过冬小妙招就是装个给力一点的空调,要么买个电热毯铺在床底下,确实没什么更好的办法。 去过一次昆明,还记得当地人说云南四季温度变化确实不大,但是昼夜温差好像挺大的?在大街上同时看到了穿羽绒服和短袖的人
-
嗷嗷是shift-jis,打错了。 感谢大佬,马上去试试
-
我去年买的天选3,现在就在用。只能说网卡这个问题是真的大,一天用的比较多的话(>4-5h),平均每天必掉一次。有时候上网课下东西之类的时候突然就断了,贼难受。。。不知道华硕怎么设计的把硬盘叠在网卡上了,可能也是为了减重吧。但是今年我把他原装的镁光的盘换成致钛之后(2T致钛系统盘+2T三星爽翻了),似乎掉网卡的次数减少了一些。 今年天选4沿用了叠叠乐的设计,那估计还是会有这个问题吧,逃不掉的。
-
就像自我介绍中写的那样,来sstm是为了学学技术,但好像还是要多发言才能解锁正经(?)内容,那就发个帖发发自学游戏汉化的牢骚把。我随便一水,各位爷也随便一听 ——————————————————————————————————————————————————————————————————— 作为一个几乎没学过计算机的人,尝试折腾这种东西实在是太难了,而且我的操作可能会让学过的人看得高血压,那就请多包涵了。 我第一个想尝试汉化的游戏,所使用的引擎是Nscripter——一个非常古早的游戏,搭配非常古早的引擎(犹记当年fate之类的大作用的也是这个引擎?)。Nscripter引擎的游戏解包倒是不难,有现成的解包软件可以直接解码到txt。主要难度在于解包出来的文本文件,执行代码和文本是混在一起的,这样翻译的时候就会把不该换的符号换掉,导致程序报错。那我就把不该翻的符号直接在Passolo里筛掉,然而源文件是Shift-JP编码的,我不知道这个编码的日文字符对应关系,Passolo似乎又没有Utf-8编码的选项,所以最后用来筛选翻译内容的正则表达式(屎山)如下: [^0-9a-zA-Z\\!@#$%^&*()_\-\=\+\{\[\}\]:;"'<,>.?/「」《》〈〉()【】±~※\n\s]+ 如果是筛选字串开头和结尾就用: [0-9a-zA-Z\\!@#$%^&*()_\-\=\+\{\[\}\]:;"'<,>.?/「」《》〈〉()【】±~※]* '匹配字串开头 [0-9a-zA-Z\\!@#$%^&*()_\-\=\+\{\[\}\]:;"'<,>.?/「」《》〈〉()【】±~※] '匹配字串结尾 然后把只有一个换行符的字串手动去掉。。。 如果筛选开头和结尾也加上\n\s的话,最后会报错:unterminated string in line xxx 总之,这坨东西目前运行的没啥问题,但就是洋溢着着一种质朴和大力出奇迹的气息,大伙就看一乐把。。。要是正好有大佬知道更好的办法,还望不吝赐教。 这次就写这么多,还有好多想吐槽的以后再发吧
-
有没有可能是清灰的时候碰到了风扇插头?之前我也自己清过一次灰,清完发现电脑用一会就会蓝屏,原来是显卡风扇插头掉了,显卡直接过热了 话说是内存问题的话不是应该直接开不了机吗?
-
硝酸羊接下了主线任务新人报到 任务链接:https://sstm.moe/topic/348095-三百字新手报到/ 硝酸羊接下了主线任务填写人物卡 任务链接:https://sstm.moe/topic/261097-新手村入村登记处人物卡/?do=findComment&comment=17276373
-
ID 硝酸羊 二次元人设 也是硝酸羊 特技 在嘴里开水泡面 找到ss的过程 仓库大佬指路推荐 崇高追求 活到退休 对坛坛/论坛的悄悄话 加油!坚持!
-
在隔壁某仓库评论区大佬的指引下来了sstm,那新人就按照论坛里一个新人报道模板介绍一下自己吧 ID硝酸羊:比较喜欢化学,之前看贴吧里一个ID叫氢氧化鸡,模仿着起了一个。 二次元、三次元的设定:二次元设定同ID,三次元设定。。。大概就是个死肥宅吧。。。 爱好是什么:acg相关的话,平时除了打打游戏,逛逛B站就没啥了,,,快乐时光一般在Fanbox、Ex很太还有隔壁站(仓库)度过。大多数时候是伸手党,但也会自购一些特别喜欢的资源投稿分享。偶尔也研究一些技术向的东西,纯粹为了好玩。做过几篇游戏攻略;自己学了嵌字、ps;最近又开始研究游戏的汉化(解包封包和机翻),顺便用app开始自学日语。 为了什么来到SS同盟:之前尝试用Passolo汉化了一个很古早的游戏(因为不会日语只能机翻),发在隔壁仓库了,但是汉化过程当中遇到了好多问题,都快气哭了。看到评论区有大佬指路sstm技术贴就来看看(不过好像要成为正式会员才能看到?)。主要过来找一些汉化的技术分享,之后也会把自己的投稿搬过来(如果能活着出新手村的话),看有没有大佬能给点建议啥的。还有就是给自己增加一点快乐时光。 什么想对SS同盟说的吗:注册之后自己逛了逛,版规真是的巨严格。。。不过这样成员发言也很认真呢。完了就是引用论坛里空空大佬那句话吧:“希望SS同盟和大家越来越好,同盟的大家能和睦相处,能够团结互爱,还有大家能拿到自己想要的东西”